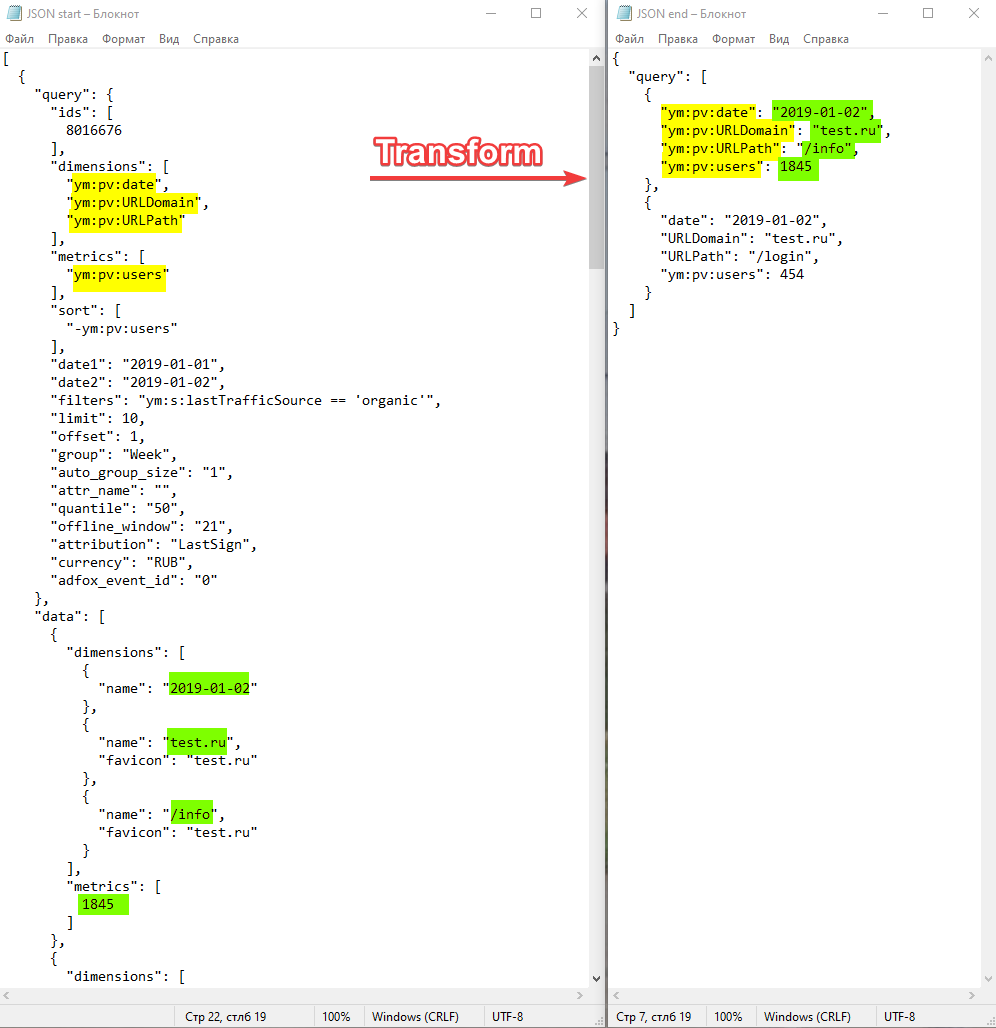
From the source I am getting a JSON file with a nested structure.
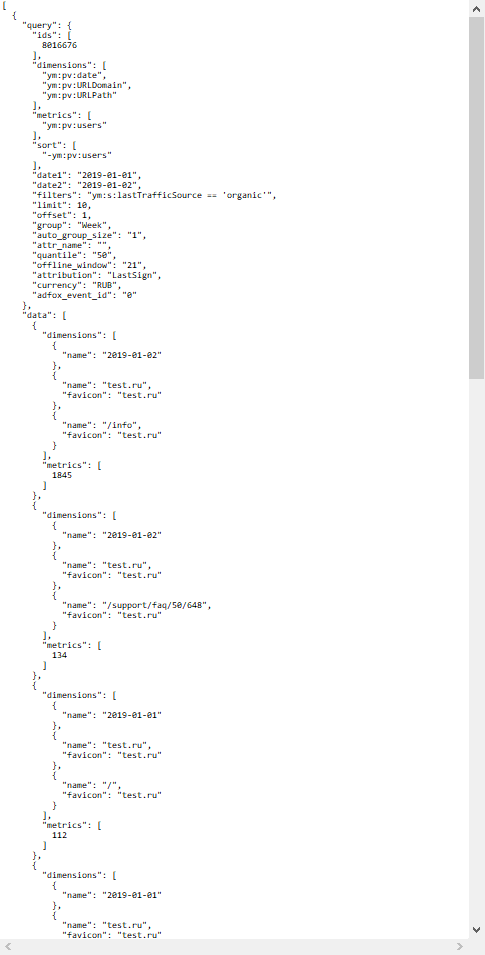
[
{
"query": {
"ids": [
8016676
],
"dimensions": [
"ym:pv:date",
"ym:pv:URLDomain",
"ym:pv:URLPath"
],
"metrics": [
"ym:pv:users"
],
"sort": [
"-ym:pv:users"
],
"date1": "2019-01-01",
"date2": "2019-01-02",
"filters": "ym:s:lastTrafficSource == 'organic'",
"limit": 10,
"offset": 1,
"group": "Week",
"auto_group_size": "1",
"attr_name": "",
"quantile": "50",
"offline_window": "21",
"attribution": "LastSign",
"currency": "RUB",
"adfox_event_id": "0"
},
"data": [
{
"dimensions": [
{
"name": "2019-01-02"
},
{
"name": "test.ru",
"favicon": "test.ru"
},
{
"name": "/info",
"favicon": "test.ru"
}
],
"metrics": [
1845
]
},
{
"dimensions": [
{
"name": "2019-01-02"
},
{
"name": "test.ru",
"favicon": "test.ru"
},
{
"name": "/login",
"favicon": "test.ru"
}
],
"metrics": [
454
]
}
}
]
To convert it to CSV format and then save it to the database, I use a loop.
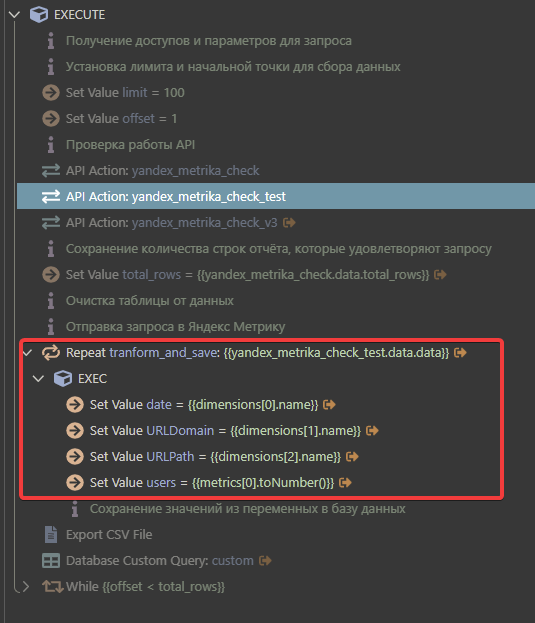
The problem is that I need to regularly save 1 million rows to the database. Cycle converting the file is taking too long.
Can you please tell me how can I change the original file more quickly?
Community Page
Last updated:
Last updated: